Introduction to workflow engines
Orchestration as a service

My colleague Oskar uit de Bos recently started a blog series on ‘an engineer’s guide to event-driven architectures’. In the second addition of this series he mentioned that one of the important skills to master to get the most out of event-driven architectures is being able to design business workflows using events. In a follow up blog, where I explained the differences between peer-to-peer choreography and orchestration, I explained that while peer-to-peer is a logical starting point for simple flows, orchestration is much better at handling increasing complexity in event flows when dealing with unhappy flows, retries, SLA monitoring, sending out reminders etc.
Besides managing the flow of commands and events, an orchestrator can also be leveraged to trigger unhappy flows. Think about retrying on error, send reminders when a manual step in the flow has been pending for too long, act on timeouts etc. Having to deal with both the happy flows, as well as all unhappy flows can soon lead to a very complex microservice. While it’s viable to build an orchestrator from scratch, as complexity grows it’s worth looking at readily available workflow engines so you can focus on coding your business specific logic.
In this blog I will explain what a workflow engine is, how they work, considerations to take when choosing between custom orchestration and a workflow engine and I will end the blog by listing some common workflow engines. Note that this blog is just an introduction to workflow engines, in follow up blog(s) I’ll dive deeper into the implementations of various workflow engines.
What are workflow engines
Let’s begin the introduction by understanding what workflow engines are. To do so, I’ll first explain what a workflow is as this is the foundation of a workflow engine. After we understand the workflow, I’ll continue to explain concept of a workflow engine.
Workflows
When googling the term workflow, you’ll come across various similar definitions. For example, the Wikipedia definition states:
“A workflow consists of an orchestrated and repeatable pattern of activity, enabled by the systematic organization of resources into processes that transform materials, provide services, or process information. It can be depicted as a sequence of operations, the work of a person or group, the work of an organization of staff, or one or more simple or complex mechanisms.”
Looking at this definition, we can see that there are a few key elements in there. The first being that it is a series of repeatable activity (referred to as tasks in the future), meaning that it consists out of multiple tasks that occur in a certain sequence frequently within your organization (or system). Secondly, the sequence of tasks processes a set of data, each step taking something as input and giving some output after the task is done. Finally, the workflow must lead to a certain goal.
Even though the definition might hint that the tasks in a workflow are all sequential, there can always be tasks that happen in parallel. If two tasks have the same inputs and can operate independently of one another there’s no reason for them not to start processing in parallel. Furthermore, a workflow can also branch out into multiple sub-flows all leading to a different outcome based on their inputs.
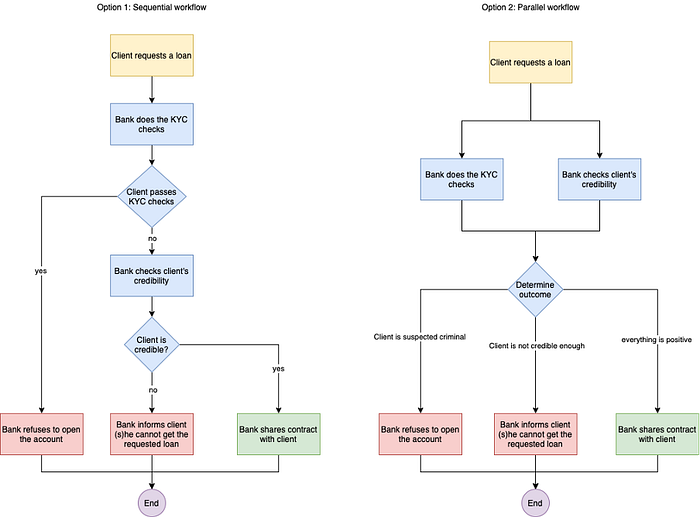
Let’s look at an example of a workflow which has a clear series of tasks, has a goal, and is used frequently within an organization. We’ll use a bank providing loans to their customers as the example. Whenever a customer requests a loan, a sequence of tasks take place to determine whether the client is eligible for the requested loan, and to be sure that the client isn’t a criminal. This sequence of events can have three different outcomes:
- If a customer fails in meeting the minimum KYC requirements, banks will have to right to refuse to open the account or to terminate the business relationship with that customer.
- The client is not eligible for the requested loan: The client gets informed that he can’t get the loan
- The client is eligible for the requested loan: A contract will be sent to the client so he can sign off on the terms and agreements before providing the loan
Figure 1 provides two different examples on how this workflow could be implemented. One option is sequential (where of course the order of the checks could be switched around), another option is the checks are executed in parallel and their combined results are processed afterwards. Furthermore, we can see that our workflow branches out to different results based on the outcome the checks.
Workflow engines
The loan request workflow discussed in the previous section is a workflow that is automated by a lot of banks. Similarly, other companies in different sectors have their own automated workflows. For example, you could think of the order-to-delivery workflow of e-commerce companies, encoding and transcribing movies at streaming services, processing batches of data in data processing companies, and the list goes on.
All these companies have faced a similar challenge at some point (and so will you once you start building such a system): “how do we ensure that our system follows the defined workflow?”. Building your own orchestrator sounds very tempting to start with, as the workflow tends to start off quite small and simple. You just add a new microservice to your landscape and make it responsible for the order of execution of your workflow by storing the progress of each task in some form of storage and triggering the next step when all criteria are met for it to start.
As the system matures, the workflow grows in terms of size as well as complexity and before you know it, you’ll spend more time maintaining your orchestrator than you are building the new tasks in your landscape. This is where workflow engines come into play. A workflow engine is essentially an “Orchestrator as a service”. To prevent developers from spending so much time in orchestrating their microservices to cope with complex workflows, the workflow engines handle all complexity that comes with orchestration internally and provide you with a simple way to define and update your workflow(s).
How workflow engines work
Now that you know what workflow engines are you might realize that they are essentially just orchestrators, so how are they relevant for me? The answer is quite straightforward: because it requires less effort. Every workflow engine is a tool developed by different organization/team, so it should be no surprise that all of them have their own implementation. However, on a high level most of them work quite similar.
Generally, the first step in working with a workflow engine is defining your workflow in some declarative format. Some engines use a JSON like structure, others use REST (which comes down to JSON as well), some expose a library which allows you to code the order in which steps should be executed and the API will take care of tracking progress and unhappy flows, and the list goes on. The workflow definition contains all steps/tasks that need to be executed, together with their order (sequential, parallel or both) and they can even hold placeholders for input parameters for each step/task. Note that these steps do not necessarily have to be automated, they can be manual steps as well. Furthermore, in the workflow definition you can also define what to do on failure like retry errors, deal with timeouts.
After the workflow is defined, the next step is to run it. How/when to start a run is entirely up to the design of your system. It can be triggered manually, time based or automatically whenever something happens (for example if a user uploads a file, start the workflow). Because every workflow engine is different, the technical implementation differs per engine, but here too most workflow engines make use of known approaches like for example REST or a library call. I mentioned before that the defined steps can have input parameters. One way to provide those is as input parameters to the workflow run. Another option is to use the output of the previous step as input to the next.
After you’ve started a workflow run, it will go start at the first step in the definition and execute it. Once it finishes, the next step will start to run automatically. Some workflow engines even provide an interactive UI in which you can track the overall progress of the run. Also, all unhappy flows defined in the workflow definition are also handled automatically. This means that if you have defined a retry mechanism for a step, a failure in that step will be retried automatically.
Considerations to decide between workflow engines or custom orchestration
After reading the previous sections, you’re probably wondering whether you should even consider writing your own orchestrator if you can just use a workflow engine to reduce the work for yourself. However, as with all things in system architecture, it highly depends on the use case you are trying to solve, as well as the situation you are in. In this section I will provide a few considerations to consider when deciding whether you should build your own orchestrator or invest in adding a workflow engine to your landscape.
The system’s lifecycle
In the early stages of a system’s lifecycle, you’re often validating a new business idea or some form of a concept. The focus is being nimble and achieving quick iterations. If this is your project, strongly consider coding the orchestration to keep the overall system as simple as possible and the knowledge threshold for new engineers to onboard low.
In later project states where the focus shifts from iterating to scaling and industrialisation, then look at the benefits that a workflow engine could bring. The obvious exception to this advice would be concepts that need a highly sophisticated workflow from the get-go.
Complexity of the workflow
Another consideration to consider is the complexity of existing workflow and future developments on the known roadmap. As stated earlier, introducing a workflow engine often means introducing a new component to your system. With this come, hopefully obvious, investments:
- In requires the existing engineers to get familiar with the engine.
- It increases the learning threshold to get new engineers productive.
- It increases operational cost, either directly if a managed service is used or indirectly as it increases operational complexity of the system
For that total cost of ownership to make sense, you either need to have or anticipate having complex workflows that would cause a significant maintenance burden on your teams or require significant development effort to build the appropriate feature-set for.
Customisability and constraints
Even though, in general, workflow engines allow you to define your specific workflow it remains a product developed by others that is designed to be used within certain constraints of its design philosophy. Which is fine if it matches properly with your problem domain, but if it doesn’t it will cause friction and frustration and results in workarounds that decrease overall robustness and scalability.
This also applied to future constraints. If possible, look at the roadmap and community communication around a workflow engine to ensure that their roadmap aligns with your future needs.
Keep orchestration and tasks properly decoupled
Looking at the reasons behind the investment decision, it’s not unlike that a significant portion of teams will start building their own orchestration while monitoring the investment tradeoffs as complexity grows. Replacing components in a system, and the associated refactoring needed, is often costly.
By having a discipline approach to building your own orchestration, you can reduce the replacement costs significantly. This is done by making sure your orchestration is decoupled from your tasks. In the implementation of your tasks should always be fully workflow unaware and completely ignorant of the overall goal of the workflow. It takes some input, does what it needs to do, and either fails or provides output. All orchestration concerns like state management, retries, notifications etc. should be fully isolated from this. If you start entangling these concerns, it will make migrating to a workflow engine, or a different workflow engine for that matter, more costly.
Common workflow engines
Before concluding this blog, I would like to present a small list of workflow engines to send you off with. As each of them could fill in a blog of their own, I will just list them and give a brief sentence or to highlighting their implementations.
- AWS Step functions: A cloud-based workflow engine managed by AWS. Workflows are defined using a JSON like syntax or using the visual editor, and the service offers a visual representation of your definition. Executions, which are also visualized, can be triggered manually, or via events.
- Azure Logic Apps: A cloud-based workflow engine managed by Azure. Workflows are defined using a JSON like syntax or using the visual editor, and the service offers a visual representation of your definition. Executions, which are also visualized, can be triggered manually, or via events.
- Google Cloud WorkFlows: A cloud-based workflow engine managed by Google Cloud. Workflows can be defined in either YAML or JSON format. Furthermore, the orchestrator uses HTTP to interact with the tasks.
- Netflix conductor: Netflix Conductor is an open-source workflow engine created by Netflix. It uses REST to define, update and start workflows (make rest calls to the engine with your workflow defined as JSON). It provides a GUI to track progress of an execution and it provides libraries for multiple programming languages which can be used to implement the integration layer on your tasks.
- Apache Airflow: Apache Airflow is an open-source workflow engine created by Airbnb. It allows users to create their workflow definitions using Python code. The workflow can be executed based on a specified time interval (Cron based) or by an external (or manual) trigger (via the cli or web UI for example). Airflow also provides a UI in which you can monitor the progress of an execution
Of course, there are more workflow engines around than I can possibly list in this blog. For example, on this GitHub page a list of open-source workflow engines has been made.
Wrapping it all up
That concludes this blog on workflow engines, I hope that the concept of workflow engines is now clear to you and, more importantly, that you understand what to consider when deciding whether to use one over custom orchestration. Stay tuned for future blogs where I will dive deeper into some of the workflow engines mentioned earlier in this blog, with some practical examples.
