Peer-to-peer choreography and orchestration
Designing event flows in an event driven microservice architecture

My colleague Oskar recently started a series on event-driven architectures. In the latest addition he shared six things that every engineer should know about event-driven microservices. One of those six items was the ability to architect event flows. In this blog I will explore that topic in much more detail.
With an event driven architecture, all microservices interact with each other asynchronously using events, with the event broker as the intermediate traffic controller. This means the microservices are loosely coupled by nature making the overall system more maintainable, scalable and extensible. However, there’s also new challenges to compose business flows using loosely coupled microservices. To deal with this challenges, different strategies have emerged as a best practice to design and implement extensible event flows.
There are two main strategies when it comes to building your event flows: peer-to-peer choreography and orchestration. Before I dive into details and providee some example implementations for both approaches, let’s take a very high-level overview and discuss the key differences between both approaches.
Similar to a group of dancers following a predetermined choreography where each dancer knows exactly what (s)he should do and when (s)he should do it, microservices following the peer-to-peer choreography pattern know exactly what they should do, and when they should do it.
The orchestration strategy, on the other hand, is similar to an orchestra (as the name implies) where there is a microservice that has the role of an orchestrator. The orchestrator microservice is responsible for the event flow, instructing other microservices to act at the appropriate moment.
In the rest of this blog, we will first dive deeper in the peer-to-peer choreography strategy, followed by the orchestration strategy. Afterwards we will go over some complex scenarios with the two strategies.
Peer-to-peer choreography
As explained, in the peer-to-peer choreography strategy all microservices will know exactly what to do, and when to do it. The microservices operate individually without being aware of the bigger system and without any centralized authority telling it what to do. Each microservices listens to the events it is interested in and performs its operation based on it. Due to this publish and subscribe nature, it is very easy to extend the system with more microservices that listen to the same events.
Let’s take a small example to show how this works. We are building a system that allows users to apply for a loan. The system will then review the request and either approve or deny it. We will start building this system in its simplest form by creating two microservices:
- The Loan request service which is responsible for handling user input (user input validation etc.)
- The Offer service which determines whether we can or cannot offer the requested loan by applying risk factors and performing additional business rules
Figure 1 shows this implementation using peer-to-peer choreography.

After setting up the core loan processing flow, we now shift our attention to informing the user of the outcome. So, we decide to extend our system with an Email service, which will take the loan approved event and send an email to our user. Since we are using peer-to-peer choreography, extending the system with a new microservices that listens to existing events is easy. Adding more and more microservices that are dependent on existing events is pretty straightforward and does not require any of the existing microservices to change. We just add another microservice to the end of our flow, and it will all work out of the box, because of the loosely coupled nature of this strategy. Figure 2 shows the extension of our system with an Email service.
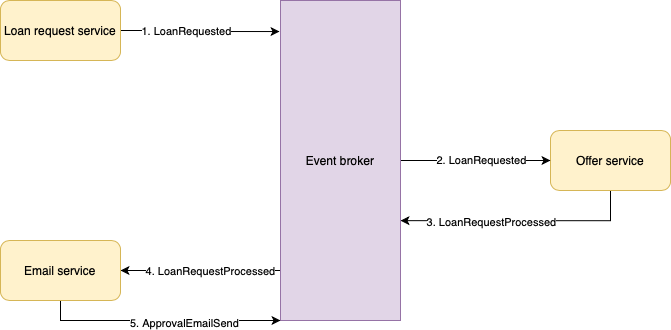
Since both the Email service as well as the Profile service work independently, there is no single point of failure in the system. If the Email service goes down for 10 minutes, the loan requests of new users are still processed. When the Email service eventually recovers, it will continue to pick up the events it missed and start sending out those emails. An important thing to take into account is that if such scenario occurs (a microservice going down while the rest of the system functions properly), it means that there could be a spike load after recovery. It is important to design your microservices in a way that can handle these spikes (for example setting a hard limit on the number of events being processed at the same time in the microservice).
At this point we have a flow that is able to process and approve loan requests and inform the users of this process. However, before we approve loan requests, we need to verify the credibility (meaning the user’s ability to pay off the loan and interest) of our user. Based on his/her credibility, we can either approve or deny the loan request. To facilitate this change, we need to add a credibility check to our system. The result of this credibility check will be additional input to the Offer service, so that we can determine the risk factors of our user more accurately. We decide to add the credibility check in a new microservice called the Credit service. Its output will be used by the Offer service to determine whether to approve or deny the loan request.
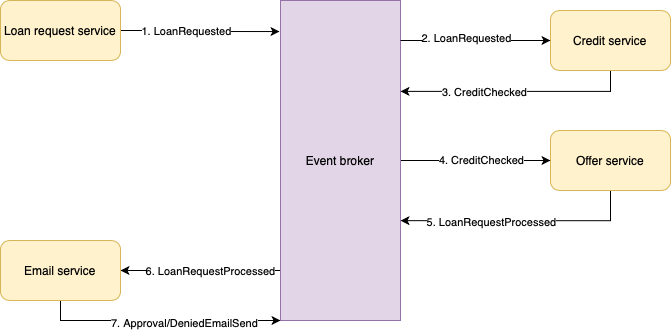
As we can see in Figure 3, changing the flow by adding a microservice in the middle isn’t as straightforward as extending the system. This has to do with the fact that even though the microservices operate independently and are loosely coupled by nature when using peer-to-peer choreography, a certain degree of coupling is still present because of the events being a contract for the microservices to collaborate. If we generalize the coupling we’ve seen, a rule of thumb for adding a new microservice would be:
- If no existing microservice needs the output of our new microservice: no changes to microservices other than the new one is needed. For example, think of either extending an existing sequential flow with another step at the end (our Email service) or introducing a new parallel flow based on an existing event
- If any existing microservice needs the output of our new microservice: at least 2 microservices need to be updated (the new one and the existing one(s) that need the output). An example of this was adding our Credit service
Another important thing to note, is that we now have 2 different possible flows we need to maintain in different places, both the “approved” flow as well as the “denied” flow need to be implemented and maintained in the Offer service as well as the Email service.
Before going into this implementation using the orchestration strategy, let’s add one more feature to our system. Since we are in the business of financing our users, we need to add at least one extra check that weighs in on whether we should or should not approve the loan request. This check is to verify whether or not the user is known or suspected to be performing criminal activities. If a user is suspected of performing criminal activities, the request should be denied, and the authorities should be informed of this user in the form of another email.
The first thing we need to do to implement this, as we are applying the peer-to-peer choreography strategy, is to add another microservice that listens to the LoanRequested event as well. There are however multiple ways to process its output:
- Solution 1: Update the Offer service and the LoanRequestProcessed event to contain extra information on whether the authorities should be informed or not and update the logic in the Email service
- Solution 2: Have the Email service listen to the CriminalActivityChecked event (output of the new microservice) and act independently on this
To show some of the challenges that can sneak in when doing peer-to-peer choreography, we will go for solution 2. The Email service will know what to do whenever it consumes the CriminalActivityChecked event. This solution is shown in Figure 4.
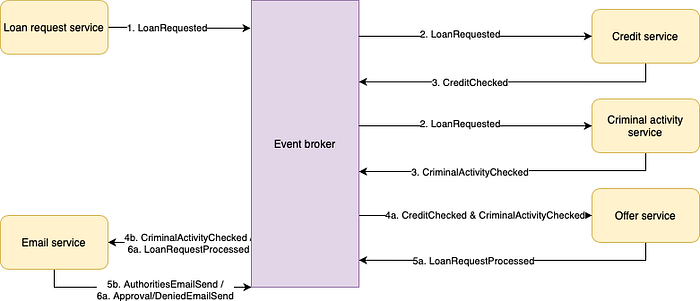
Even though we have a system that works perfectly fine, with every addition we make (especially the additions of parallel flows like we just did) the complexity increases, and our systems gets harder to understand. Just imagine what happens if the Offer service only receives one of the two events. Since it depends on two events to start doing something, it has to deal with eventual consistency and out of order events, next to its own responsibility and complexity. And what happens if we decide we need a manual intervention to verify whether the criminal activity checked is not a false positive, we will have to update at least three microservices (Criminal activity service, Offer service and Email service) to deal with this change. How do we keep track of such scenarios and where a user’s request possibly failed?
Before we discuss scenarios like these, let’s summarize what we’ve learned implementing our system using peer-to-peer choreography and implement the same system using the orchestration strategy. Having seen the evolution of our system using peer-to-peer choreography, we have seen some of its strengths and challenges in action:
Strengths:
- It’s easy to extend the system with new functionality without having to adjust any other microservices
- The autonomy of microservices results in high overall availability
- There is no single point of failure
Challenges:
- Understanding everything that happens in the system becomes hard over time
Orchestration
As opposed to the decentralized nature of the peer-to-peer choreography strategy, the orchestration strategy relies on a single, centralized microservice that orchestrates the workflow. The sole responsibility of this orchestrator is to listen to events that happen in the system and send out commands to other microservices to start performing their task.
Figure 5 shows how our initial, simple loan request flow would look like when following the orchestration strategy.
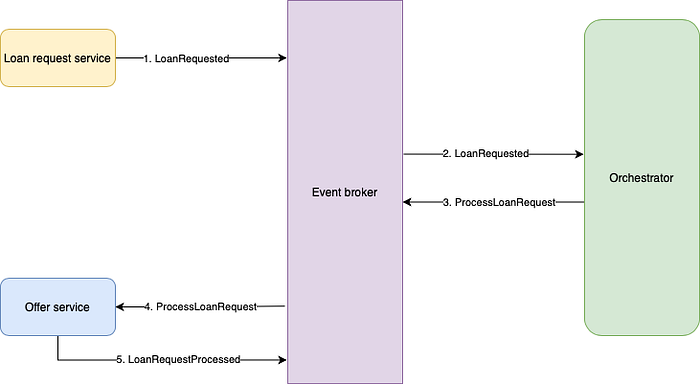
Comparing this flow to the choreography implementation, the main differences lie in the fact that the Offer service no longer listens to the loan requested event. Instead, the orchestrator listens to this event, and sends out a command to the Offer service to start performing its operation. Looking at the design with a critical eye, it might actually seem like an overkill to have an orchestrator for such a simple flow. Let’s extend the flow with the Email service in figure 6.
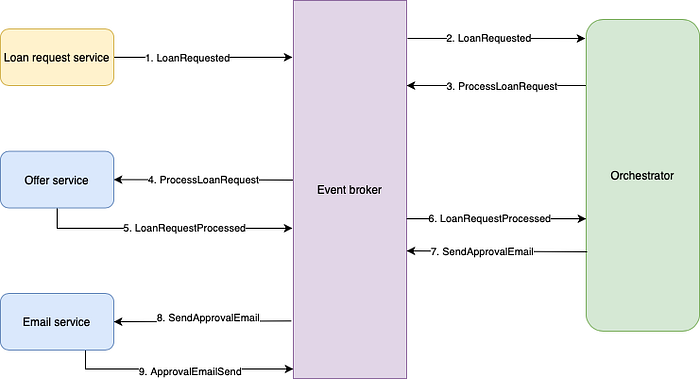
Here too, the orchestrator listens to the user registered event and sends out two commands (where an event communicates that something happened, a command communicates that something needs to happen) for the other microservices to start performing their action. As opposed to the choreography strategy, where one microservice going down has a minor impact on the overall availability, the orchestrator going down for 10 minutes would result in the whole system being unavailable for 10 min since both the Offer service as well as the Email service will not receive any of the commands to start working. Besides that, we can also see that extending the system in the peer-to-peer choreography strategy meant only adding a new microservice that listens to existing events, using an orchestrator means that this extension impacts two microservices.
If, like before, we continue to update our system by adding a Credit service we notice something interesting. Even though extending a system using peer-to-peer choreography requires less (no) changes to existing components, altering the workflow means changing (at least) two microservices in both strategies. Where in peer-to-peer choreography, adding the Credit service before the Offer service meant updating those two microservices, and updating the rest of the existing flow to deal with this newly created alternative flow, in our orchestration implementation it means adding the new microservice to our system and updating the orchestrator to deal with the different workflows. In other words, the number of updates is almost the same in both cases! Figure 7 shows how our systems looks after we’ve added the Credit service.
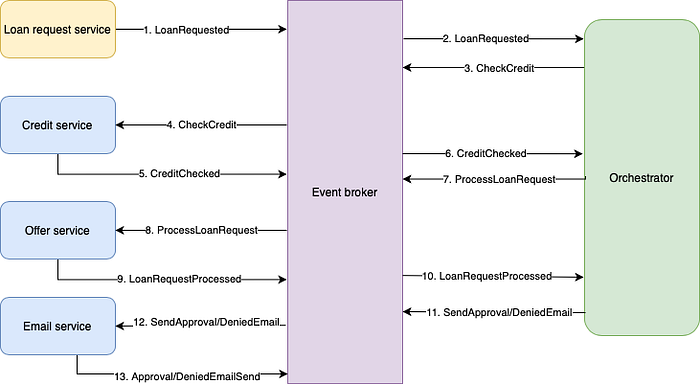
To finalize our system, let’s end by adding our criminal activity flow to our orchestrated system. Just like with the Credit service, this means adding a new microservice and updating all microservices that depend on its output (including the orchestrator).
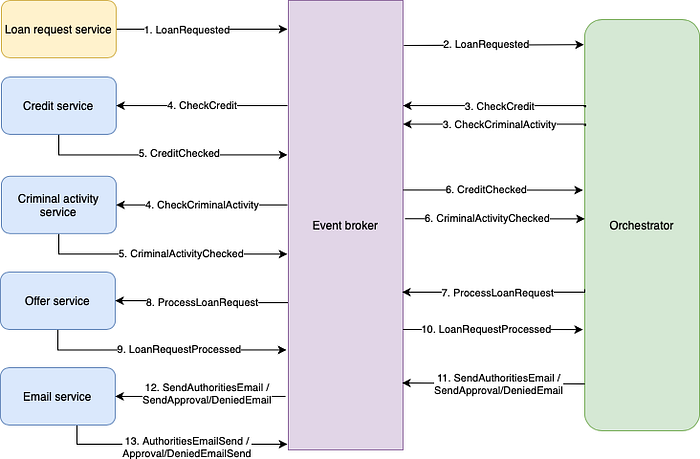
When dealing with larger systems that require complex flows, the orchestration strategy gives you the great benefit of centralizing both the flow coordination, making it easier to understand what happens when. In addition, as the orchestrator centralizes the workflow logic, the risk of getting distributed business rules is reduced. Of course, these benefits also come with limitations, where your system is not as extensible as it was before (adding the Email service required both creating the Email service as well as updating the orchestrator). Besides being less extensible, there is also the matter of having a centralized microservice responsible for coordinating the flow, meaning that there is a single point of failure in the system.
Complex scenarios
So far in this blog we have covered how to build and evolve event flows, and some pros and cons of both strategies. However, as systems become bigger and more mature, we always tend to get to a point where we hit more complex scenarios like:
- Implementing non-happy flows where a technical error happens halfway through the flow
- Being able to automatically act on incomplete processes
- The need for SLAs and metrics to measure the system’s performance and health
- Building and maintaining a custom orchestrator or leveraging a workflow engine
In this section, we will briefly go over these four scenarios and explain how to deal with them using both approaches.
Non-happy flow
If we take a look at the final design of our loan request system, there are a lot of things that can go wrong. Let’s take a non-happy flow to explore further — what happens if an email fails to send due to an unexpected error, or even worse due to a network issue the event never arrives in the Email service.
In both the peer-to-peer choreography and the orchestration implementations, the unexpected errors can be tackled by applying some form of retrying on the Email service itself. This retrying behavior can range from something as simple as not acknowledging the event and processing it again upon failure, to more complex implementations like implementing a dead letter queue which gets retried every x amount of time.
What is harder to tackle using peer-to-peer choreography is the scenario where an event gets lost (due to a network hiccup or a consumer that acknowledged an event right before it died off for example). Because each microservice is unaware what happens to the rest, there is no simple solution to automatically recover from this due to the fact that the microservice that missed the event, is unaware of the fact that it missed it.
In the orchestration implementation on the other hand, these types of failures (as well as timeouts and the need to rollback certain actions) are easier to detect and to be acted on automatically because the orchestrator is aware of what has happened, and what was supposed to happen. For example, if we expect the email to be sent within at most 5 minutes, it’s easy to check whether the email send event has been produced at within 5 minutes after the send email command was produced. Do make sure that your events are idempotent to prevent accidental retries in such cases (we don’t want to send the email out twice because our Email service took longer than expected).
Acting on incomplete processes
Just like unhappy flows due to errors in the system, acting on incomplete processes is easier to do with the orchestration implementation. Let’s say that after we approved the loan request and we’ve sent the email to our user, we expect our user to acknowledge the offer. Since the orchestrator knows exactly when the email was sent, we can send time-based reminders to the user if (s)he did not approve the offer after x days. The same holds for a process that gets stuck halfway through due to a manual intervention that is needed, for example if we want one of our employees to double check randomly selected credit checks on false positives. The logic works similar to the earlier discussed timeout scenario. If after x period a manual intervention did not take place, send a reminder to make sure the process gets completed. In peer-to-peer choreography this becomes harder because the information about the full flow is distributed, so a microservice is not aware that a flow is incomplete.
SLAs and metrics
As the system matures, either you as the developer, or the business, will want to have some metrics and numbers on the performance of the system. This can of course have multiple reasons like defining an SLA, understanding the bottlenecks in the system, being able to see whether all microservices are healthy etc. In the peer-to-peer choreography implementation, the only way to get this information is to have every microservice export its metrics to a centralized monitoring system. In the case of our loan request system, from the Loan request service all the way to the Email service, all microservices need to export when they started processing an event and when they finished. By aggregating this information, we can than create a dashboard that gives us the insights we need. Although this solution also works for the orchestration implementation, it can be done easier. The orchestrator is already aware of everything that has happened, and when it all happened. In other words, all the metrics that need to be exported and centralized in the peer-to-peer choreography implementation are already present in the orchestrator itself. This means that all we really need to do is to visualize this (or export this information from the orchestrator to the monitoring application to save us some visualization time).
Custom orchestration and workflow engines
When implementing the orchestration strategy, especially for a simple flow as the loan request system we’ve just designed, the orchestrator can be implemented by simply building another microservice that coordinates the rest. However, as your system grows and the flows become more complex, it can be worth it to start looking into open-source workflow engines like for example Netflix’s Conductor, Apache Airflow, Argo and Camunda (of course the list is longer than this) or even workflow engines provided by cloud vendors like AWS Step Functions, Azure Logic Apps and Google Cloud Workflows.
One of the reasons to consider this movement to workflow engines is that at some point, a lot of time and effort will be spend on updating the orchestrator instead of building the functionality that fulfills the business needs. Workflow engines often have a simple way to define the steps in a workflow via either a graphical user interface or a domain specific language (Netflix conductor for example is REST/JSON based). Often times defining and updating workflows like this is both faster and reduces the risk of making a mistake. The flip side of it is that we need to add a new component to our landscape and, like most out of the box solutions, they won’t always fit your use case.
In conclusion
In this blog we dove deeper into the two main strategies when designing event flows, peer-to-peer choreography and orchestration, where they excel and what their drawbacks are and what considerations to take into account when choosing the strategy that works for you. It is important to know that both are tools to keep in your pocket to use at the appropriate times. We didn’t go into it explicitly, but they can even be combined in some cases like having an Audit service listening to all events in a peer-to-peer choreography style where the rest of the system follows the orchestration strategy. Just be careful when doing this, as mixing strategies can make things more complex.
In future blogs I will discuss popular workflow engines, like ones mentioned earlier, and what their added value is compared to doing it yourself.
